鄭碼的次末根取碼法對降低重碼究竟起多大作用
原發: http://www.pkucn.com/viewthread.php?tid=275232
鄭碼是典型的雙碼字根式形碼。所謂雙碼,就是最常用的字根(鄭碼謂之主根,分第一、第二兩套:26×2+)配上一個字母,其他字根(副根)配兩個(個別為三個)字母,首碼稱區碼,餘者稱位碼。
鄭碼也是定長碼,每辭條最多四碼。受定長的限制,字不能皆取全部字根,字根也不能皆取全碼,於是它就設定了若干條針對雙碼字根的取碼規則。
下面只談它的完整單字碼(五筆所謂全碼),不討論它的詞碼、簡碼。
中易的原始規則可概括如下:
- 0,字碼最長為4碼
- 1,首根取全碼(1-3碼)
- 2,首末之外的中間字根只取區碼(1碼)
- 3,末根的區碼必取。末根為副根時(2-3碼),若前面所取的字根碼少於3碼,則依次取其區位碼,直到字碼湊足為4碼或末根碼取全為止。
4,原則上各字按「首,次、次末、末」根的次序取碼。不足四根的字,只取其存在字根的碼。
首,次、次末、末 重,輕← 次重← 重
因首根取了2碼或3碼,次、次末、末三根不能全取的,依上圖所示的權重值,按由輕到重的次序略掉必須省略的字根(如4碼以上的字,首根3碼,則略次、次末根,首根2碼則略次根)。
五筆也是定長為四碼的字根碼,但它的字根選取次序和權重值卻與鄭碼截然不同,如下圖:
首、次、三,末
重→次重→輕,重
不單是我,恐怕大多數人相對而言都更容易適應五筆式的取碼法。可能因為,按着這種次序進行拆字分柝,思路與書寫序相符,雖有跳躍卻無逆反。而按鄭碼的取碼法,作拆字分析時,往往須要先確定末根,然後憑藉末根纔能找到次末根。這種迂曲的思維方式無疑是一種腦力負擔。
有人說鄭碼的之所以看重次末根,是出於減少重碼的考量。我一直以來就對這種說辭抱持懷疑態度,無奈於空說無凭,只好不置可否。所幸昨日找到了一份至至的《常用漢字鄭碼字根分解表》,該表列出了gb2312全部漢字的完整鄭碼字根分解,和每字各字根的完整區位碼。我受了伽利略鐵球實驗的鼓舞,一時興起,就利用這個表寫了一個自動生成鄭碼單字碼的腳本,可分別按鄭碼的原始取碼序和類似五筆的「首次三末」序兩種規則生成字碼表。我將生成的兩種gb字表的重碼進行了對比,發現「首次次末末」序的字碼的確比「首次三末」序的字碼重碼要少一些。然而究竟少多少呢?
原序字碼表重碼325組
改序字碼表重碼342組
只少17組,17/342 ≈ 1/20。
diff 一下:
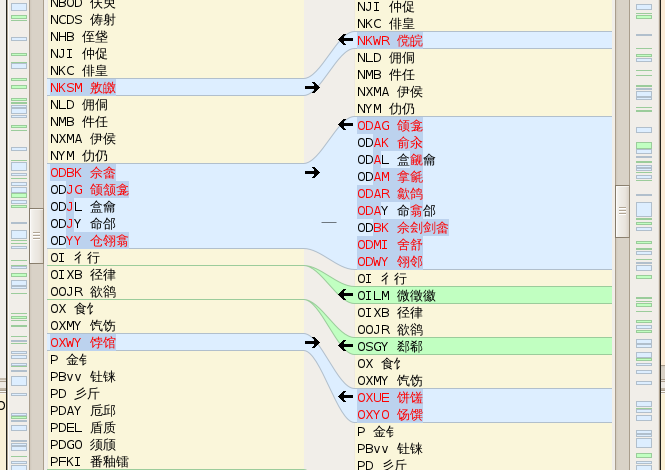
原來改序而多出來的重碼多是這樣一些字
ODAG 颌龛
ODAL 盒觎龠
ODAM 拿毹
ODAR 歙鸽
ODAY 命翕郃
ODBK 佘刽剑畲
ODMI 舍舒
合頭𠓛 od a 三碼 &
SHJQ 嬴羸蠃赢
SJRH 哀衷
SJWQ 亮膏
SJYU 烹熟
次末碼可避開𦝠框、高框
XSXF 柔桑
XSXG 豫预颡
XSXI 予蝥蟊
XSXL 叠瞀矞
XSXR 鹜鹬
XSXX 矜骛
矛字要拆成折、點、折、豎、撇,這難道不是字根設計上的問題?
諸如此類,我就不一一列舉了。本實驗的資料和工具己打包上傳,歡迎有興趣的網友下載研究。
blog comments powered by Disqus