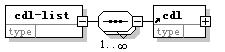漫谈XML在中文信息处理中的应用 - 述而
漫谈XML在中文信息处理中的应用
(一篇舊文,權供參考)
原發於: http://www.pkucn.com/viewthread.php?tid=156533
samples
包含:
pkurss.xml--北大中文论坛RSS文档
showrss.xsl
showauthor.xsl
showtitle.xsl
-----将XML转换成HTML格式的样式表文档
xxx.doc,主贴的word文档
Title: Ramble in Chinese Literature/Ideography Information Processing with XML technology
Keywords: Chinese Literature/Ideography Information Processing; XML; CDL; TEI; Docbook; DTD; XSL Schema; XSLT; RSS……
Motive※动机
————首先必须说明,我对XML技术的认识程度也只停留在业余水平。之所以要写这篇文章,一方面是因为至少在本论坛本版,这个领域是一个老大的亟须填补的空白,大公鸡们不玩活计,说不得只好由小牝鸡来司晨。另一方面,毕竟自己委实花了一点心血和可观的时间来学习这门技术,瞅準适当的时机把紊乱的思维梳理成文也不失为一种巩固知识的有力手段,也算是对自己的一个交代。
For What※原旨
————XML 的全称是 eXtensible Markup Language , 译作 可扩展标记语言。一提到这语言那语言的,总容易使人联想到软件、指令、语句、编程、程序员什么的。其实XML本身并不是面向程序设计的语言,它的前身是SGML——STANDARD GENERALIZED MARKUP LANGUAGE ,汉译 标准通用标记语言。本文的题目是“漫谈”,没有必要罗列概念,也无须详述 XML 的发展历程,提 SGML 的原因是为了借 generalization这个词说事。Generalization 顾名思义,就是一般化的非特定目的的。XML实际上——确有这么一说——就是 SGML的一个子集(subset)。光从那个X上是看不出什么门道来的,不如拿一种非一般化的标记语言对照着看。譬如HTML吧,这门语言我想就用不着多介绍了,常来本版面冶游厮混的哥们,想必都懂得这个acronym含义。SGML—XML—HTML,这里边有什么玄机?不错,markup language不是白叫的,这三位委实是沾亲带故的。新版本的 HTML—XHTML—eXtensible HyperText Markup Language 就是 XML的一个子集。不过Subset这个词还是容易引起误会。若以人类语言做比,XML相当于抽象的语言,譬如手语、屈折语、声调语言、小儿语、黑话、秘密语等,而HTML则类似具体的能听得见看得着的语言,如屈折语中的法语、秘密语中的盲佬话、手语中的台湾手语等。也就是说,XML本身不包含具体的词汇、语法。那它究竟是个什么东东呢?
XML只规定语句的格式和语句之间的组合形式。下面是XML“语句”的基本句法。[]中是可选内容,斜体字是语言要素的说明性类属名。
<tag [attribute(s)] > …content…</tag>
接下来是一则XML语言的文档实例
(例一)
<? xml version=”1.0” encoding=”UTF-8” ?>
<note>
<to> 王小鸭</to>
<from> 李鹅</from>
<heading> 提醒</heading>
<body> 别忘了我们周末的约会</body>
</note>
第一行被<?...?>标记的内容称做操作指令(processing instruction) ,在本例中的作用是声明XML的版本(1.0)和编码格式(UTF-8)。
一对尖括号连同其中中的文本称作一个标记(tag) ,如, 。
“note ,to, from, heading, body……” 都是 标记名。
“<”后紧随出现“/”的标记叫做尾标记,没有斜线的叫首标记。
标记总是成对出现,如<note>…</note>,首、尾标记加上中间的内容构成一个元素(element) 。
元素可以没有内容,这样的元素被称作空元素,可以写成<tag_x />或<tag_x></tag_x>,这两种格式都是正确的。
元素中可以包含其他元素,如上例中的王小鸭… 嵌套(nesting) 。
以下是www.w3schools.com 中给出的XML基本文规:
所有元素都必须有一个尾标记(老版本的html对此不太在意,新的xhtml恪守XML的所有规则)
XML标记(名)是大小写敏感的(譬如:≠, 和 不能匹配。 xhtml 要求所有的标记都使用小写字母。)
所有元素都必须正确嵌套(如: .. ....
所有的文档(XML文档)都必须有一个,而且只有一个根元素(如上例中的元素,<?..?>操作指令不是XML元素,所以可以(且必须)出现在根元素外。)
属性值(attribute value)必须写在雙引号中(比如,我们可以给例一的根元素加上一个日期属性:… ,“date”的值必须被引号包围)
在XML中空白被原样保留( 别忘了 我们 周末的 约会 ≠别忘了我们周末的约会)
在XML中 CR/LF(回车/换行)被转换成LF(换行)
注释的形式为
我的补充:
需要的话标记名也可以使用汉字,如可以写成<備忘>,但最好不要这样做,为了避免不必要的麻烦应尽减少对非标准拉丁字母的使用。当然标记名中可以出现数字,但第一个字符不能为数字。
通过前面的叙述,我不说诸位也能清楚,标记名是用户任意起的。这就是为什么说XML是general而xhtml是special的原因。
好了,说到这里是时候揭晓节标题的答案了。Q: For what | A: For ANYTHING, for EVERYONE!! Yes,就因为这是一门如此灵活,绝无死板规定的语言——灵活并不意味着不严格——所以我们可以用它在做任何事情,当然也包括汉语言的文字和文献的信息化处理。
XML好就好在它给所有的“标记语言”提供了一个坚实的框架,而对语言的内容和功用没有任何的限定。
Why markup※为什么要打标记
这个问题几乎用不着回答,想想我们在回贴的时候为什么要加上[ quote]…[ /quote]和[ url=xxx]..[ /url]吧。简单的解释是:引用和连接与正文有着不同的功用。其实这么说是缺乏想象力的表现。Discuz的标记语言给我的感受实在是弱得不能再弱了。我们想表达的东西原本是那么的丰富,就拿表格来说吧,没法子,我们只好以截图的形式贴上来。但贴在BBS里的image跟书里的插图又有什么两样呢?有着丰富内涵的信息被迫形式化了。
难道标记的最终目的就是为了使你的文档看起来更花哨吗?不!如果这就终极的目的,我们完全没有必要跟XML打交道,?TML 、WORD或是PDF就足够了。这里涉及到几个需要辨析的概念:内容、数据、格式。
还是举例说明。要举就举个有实际意义的例子。这次我选中了RSS。呵呵,您的耳朵可能已经被这个怪模怪样的acronym磨出茧子来了。那么,先解释一下什么是RSS。
(本例的假想读者是对RSS不甚熟悉,或尽管使用过RSS READER而对它的工作机理仍不甚了了的朋友,如果您已经对这一切了如指掌了,请您别声张,假装不知道好了_)
RSS stands for Real Simple Syndicate (真正简单的辛迪加)。RSS跟XHTML一样,也是XML,别犯糊涂,想想我之前举的例子,法语、德语都是屈折语,但屈折语不等于法语。
请您先回到本站的主页。在页面的左上角有一个橘红色的小banner,在浏览器中单击它,看看会出现些什么?
(行动之前请最好先记住本文的标题,免得您迷了路看不到下文了。难道人家还不知道浏览器的back功能吗!呵呵,我这是以愚公之心度智叟之腹了:))
如果您的浏览器支持xml,您看看到的将是类似下表的文本(具体内容会定时更新)
(例二)
<?xml version="1.0" encoding="gb2312" ?>
- <rss version= "2.0" >
- <channel>
<title> 北大中文论坛 www.pkucn.com</title>
<link> http://www.pkucn.com/index.php</link>
<description> Latest 20 threads of all forums</description>
<copyright> Copyright(C) 北大中文论坛 www.pkucn.com</copyright>
<generator> Discuz! Board by Comsenz Technology Ltd</generator>
<lastBuildDate> Fri, 7 Oct 2005 15:46:20 +0000</lastBuildDate>
<ttl> 10</ttl>
- <image>
<url></url>
<title> 北大中文论坛 www.pkucn.com</title>
<link> http://www.pkucn.com/</link>
</image>
- <item>
<title> 模仿柏拉图的对话录,希望大家指教。</title>
<link> http://www.pkucn.com/viewthread.php?tid=156528</link>
- <description>
小弟我模仿柏拉图的对话录的方式所谈的个人的对于诗歌的浅显之见,希望大家指教。
苏格拉底篇
对话人:巴克科斯(作者之托称)
苏格拉底
巴:欢迎你,赤足的行者,你难道就是那个著名的苏格拉底吗?
苏:不错,正是。我刚刚从雅典出来。人们为了宙斯的女儿,雅典的守护神雅典娜举行盛大的庆典,同时举办了戏剧及各种技艺的竞赛。
巴:真是让人期待的盛会。你可曾去聆听了美妙的诵诗?
苏:当然,我不会错过这么一个绝佳的机会。你知道我是一个关心诗歌的人。
巴:我知道。我也看到你的脸庞还因为兴奋而通红,看到你 ...
</description>
<category> 文艺学</category>
<author> MrG</author>
<pubDate> Fri, 7 Oct 2005 15:25:55 +0000</pubDate>
</item>
- <item>
<title> 可爱的龙三老先生</title>
<link> http://www.pkucn.com/viewthread.php?tid=156527</link>
- <description>
l了
ls啰嗦
lsl落水啦
lslx蓝色理想
lslxs龙三老先生
lslxsz龙三老先生真是个可爱的老头,他就喜欢王大妈裹脚又长又臭!
</description>
<category> 输入法讨论专区</category>
<author> 张德明</author>
<pubDate> Fri, 7 Oct 2005 15:10:09 +0000</pubDate>
</item>
- <item>
<title> 匏瓜徒悬 志士悲歌!</title>
<link> http://www.pkucn.com/viewthread.php?tid=156526</link>
<description> 今天读王粲的《登楼赋》:中有 匏瓜之徒悬兮,旨喻志士怀才不遇,感慨颇多。有秦以来,诸子士庶大都怀此感此情,所谓发奋所为,著书立说。若无此,古代文学或许仅仅是空梦一场!</description>
<category> 初学问津</category>
<author> 凤舞九天魂不悔</author>
<pubDate> Fri, 7 Oct 2005 14:37:17 +0000</pubDate>
</item>
- <item>
<title> 鹊踏枝◎赏两幅荷花摄影图</title>
<link> http://www.pkucn.com/viewthread.php?tid=156525</link>
- <description>
鹊踏枝◎赏两幅荷花摄影图
2005.10.07
一顷黛荷秋水上。逶迤洇浓,醉了莲枝舫。霓桨摇云天荡漾。姮娥欲饮西湖酿。
莫向中宵深处望。寸寸生凉,风露横相向。仙子捧来珠泪晃。泠泠只在波间葬。
</description>
<category> 旧体诗词原创</category>
<author> 灏子</author>
<pubDate> Fri, 7 Oct 2005 14:27:32 +0000</pubDate>
</item>
……..原表过长,此处省略
</channel>
</rss>
呵呵,这就是大名鼎鼎的RSS拉,看起来好象一碗杂碎面呐。别着急,按着我的提示您很快就能读懂它了。
首先,请您先活动活动鼠标滚轮,找到这篇文档的第一行。眼熟吧,如果您认真地读了前文的话,您大概能脱口而出,它是……操作指令。跟例一中的那一条还有点不大一样,encoding=”gb2312”,这可难不倒我们“中文信息处理版”的网友。
接下来,您再看看第二行和最后一行: 和 ,这就是RSS文档的根元素。
下一步是寻找第一个- 元素,找到首标记和尾标记,看看
- 中都包含了些什么内容,然后再找到其他的
- ,比较一下,您会发现,所有的
- 都采用了相同的构造,就如下表所示:
<item>
<title> …</tilte>
<link> …</link>
<description> …</description>
<category> ..</category>
<author> …</author>
<pubDate> ..</pubDate> **
</item>
**发表日期,实际上是时间+日期=post time
不要理会<description>中的<br />,这是本论坛RSS的BUG,前文已说明,XML中的空白(包括换行)是被自动保留的。
标题、连接、摘要、类属、作者、日期——这些都“象征”着什么呢?对了,我还没介绍RSS是干什么用的呢?它实际上是一种随时更新的catalog(卡片索引),适用于做BBS、新闻网站、blog 或者更新速度较快的网站文章库的导读卡片。对这种索引卡片而言,最重要的当然也就是“标题、摘要、类属、作者”之类的信息了。图书馆里传统的索引卡片是通过索引号码来获取图书的。在RSS中
但是,这里的连接怎么点不了呢?
附件中有一个showrss.xsl文件,请先把首页上的RSS文档保存到一个指定的目录(文件夹中)将扩展名改为 .xml。然后将showrss.xsl 解压到相同目录下。接下来,用一个平文本编辑软件(比如notepad)打开 RSS文档,在第一行的操作指令后插入
<?xml-stylesheet type="text/xsl" href="showrss.xsl"?>
该操作指令表示加载文档时读取 showrss.xsl样式表,并根据该样式表设定的格式(布局)将RSS的内容输出到浏览器。保存更改后的RSS文档。用支持XML 和XSL的浏览器(如IE6)打开它,看看我们折腾了半天究竟得到了什么?
很难看的布局,是吧。不过至少比那碗杂碎面强点,好赖连接是可以点了。点一点试试。OK!Mission accomplished!
内容——我们在帖子里码的字儿应该算是内容吧。
数据——用作者、摘要、类属、日期什么的打上标记的东西是不是有用的数据呢?
格式(包括布局)——这里所说的是最终的可见形式,它当然也很重要,但对RSS而言这是细枝末节的东西。附件中还有showtitle.xsl和showauthor.xsl两个样式表文档,有兴趣的话可将读取样式表的操作指令更换成<?xml-stylesheet type="text/xsl" href="showtitle.xsl"?>或<?xml-stylesheet type="text/xsl" href="showauthor.xsl"?>
试验一下!
原来内容跟形式完全是两码事啊。内容不受制于形式,这就是XML标记语言的神髓!!
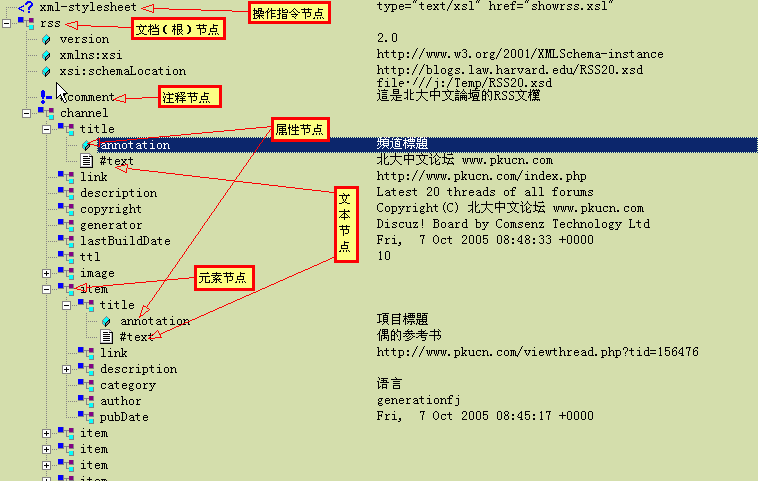
〖圖一〗
How※机理
信不信由你,我说这是一棵树。换句话说,它就是上文例二(北大中文论坛RSS文档)的树状图解——西文称作DIAGRAM。为什么要在这儿鼓捣出一棵来呢?请诸位少安毋躁,听某细细道来。
应盛金标版主的要求,我应该马上切入主题解说CDL语言的原理了。不过,为了把包袱抖响,扑平垫稳的功夫是省不了的,还是容我是先解释几个必要概念。
1. 对XML基本句法的进一步说明:
<tag [attribute(s)]>[…content…]</tag>——这个公式的意思是,一个XML元素由标记和可能包含的内容构成——有时候元素一词被用来兼指元素体和标记名;首标记中可以选择性地添加一个或多个属性;属性的的句法是 name=“value“——也就是所谓的名、值组合;内容也就是正式的数据——一谈到数据,必然涉及到“数据类型”这一数据处理中的核心概念,这部分内容较为复杂,留到后文详述。
2. 元素的组织形式:
XML法则中的“文档中必须且只能有一个根元素(又叫文档元素)”和“一切元素都必须正确嵌套”的规定决定了XML文档的元素必然按树状关系组织,一篇XML文档就是一棵树。比如例二所引的北大中文论坛RSS文档,其中的所有元素分别扮演了根、茎、枝、叶,合起来共同构成了如图一所示的这么一棵树。树状结构暗示着一个等级制度(Hierarchy)——或者叫层级体系(Cascade),在XML中,相对高的等级对相对低的等级而言是包含关系。
3.节点:
图一中的任意一个图标和与图标相连的向下或向右的延长线(如果有的话)上的所有图标(包括没有展开——左侧标有加号的——一系列图标)合起来构成一个节点(node)。这里之所以说图标而不说元素,是因为图解中的图标所对应的不光是元素。比如突出显示的“annotation”图标是一个节点,但不是元素,它是上一级节点”title”元素的一个属性,而下面仅邻的”#text”节点则是”title”元素的内容。由此可知,属性和元素的内容也构成节点。实际上XML一共定义了7种形式的节点:A)文档节点(根节点)B)元素节点C)属性节点D)文本节点(文档树中最低一级的元素节点,如果包含文本内容,则该内容称作文本节点)E)注释节点F)操作指令节点G)命名空间节点(本文不打算深入讨论与此相关的内容)。其中的E 和 F 不是XML文档的组成部分。图一中的每一种图标对应一种节点,详见红色方框中的标注(命名空间类节点除外)。
4.修正:
因为节点和元素是对XML文档从两个不同的角度进行分析所用到的不同的概念,所以必须明确,树-节点是一个体系,元素-属性-内容是另一个体系。回到XML元素的基本句法上来,参照才刚对XML文档树状结构的分析——做为最低级元素节点内容的文本是节点,相应的属性也是节点,那么,XML文档中真正的数据节点就是文本节点和属性节点,反过来说,属性和文本都是数据。
比如,图一突出显示的元素节点所对应的XML语句为:<title annotation=”項目標題”>偶的参考书</title>。该元素中的“項目標題”和“偶的参考书”都是有用的数据。该元素的文本内容称为元素值,而annotation的值则称作该元素的属性值。
绕得我自己都迷糊了,说得浅白一点,也就是XML提供了安排数据的变通方式。如,我可以把title元素改写成<title><annotation>項目標題</annotation>偶的参考书</title>或者<title annotation=”項目標題” text=”偶的参考书” />的形式。它们的功能是等效的,但后两种写法不符合RSS的规定,不能被RSS的阅读软件识别。
(_^ 其实 <title annotation=”項目標題”>偶的参考书</title>也是非法的。RSS中的任何元素都没有属性,“annotation”是我为了说明的方便临时加上去的。这是小可customize的RSS,喜欢的话您可以把它叫做RSS+)
打这儿又引出来一个话由儿:好比都是苹果树,但树和树是一样的么?当然不一样,枝杈的架势不一样,每个枝儿上挂的果子也有多有少不是。那么,树的“架势”是怎么规定的呢?XML中的相关技术是DTD(Document Type Definition)——文档类型定义和 XML Schema——XML架构。两者的功能仿佛,前者的历史更悠久一些,但采用了特殊的一套语法,后者势头强劲,本身就用XML编写,也是XML的一个SUBSET。
按 www.w3schools.com的说法,XML Schema :
+ 定义了哪些元素将出现在文档中(xml文档,下同)
+ 定义了哪些属性将出现在文档中
+ 定义了哪些元素是哪些元素的子元素
+ 定义了子元素的顺序
+ 定义了子元素的数目
+ 定义了一个元素是空元素还是包含文本
+ 定义了元素和属性的数据类型
+ 定义了元素和属性的缺省值和固定值
一句话概括,DTD或XML Schema是用来定义特定目的的XML语言的。
RSS、CDL和盛版主刚刚贴出的“北京大学汉英双语语料库标记规范”都属于特定目的的XML语言,或者说都是XML的 SUBSET。在XML的基础上可以自己创造语言,这正是它最吸引我的地方。不过请诸位注意,北京大学汉英双语语料库标记规范 的说明书可不是用来定义语言的,它并未提供DTD或XML Schema,它只是对可能存在的DTD或XML Schema的说明。自然语言的说明是松散的随意的,而DTD或XML Schema是一丝不苟的,有了DTD或XML Schema,我们就可以对编写好的XML文档进行验证,符合上文所引述的XML基本文规的文档被称作是well-formed,而通过了DTD或XML Schema验证的文档则被称作是validated.譬如我的RSS+就不可能通过RSS.dtd 或RSS.xsd (XML Schema的扩展文件名是xsd)的验证,但它还是well-formed的,如果心情好的话,我把RSS+的DTD或XML Schema编写出来,则我的文档将通过RSSPULS.DTD验证成为validated的RSS+文档
CDL※字符描述语言
本文不打算讲DTD或XML Schema,况且我对DTD是一窍不通的,只些微知道一点Schema的规则。
但是要讲CDL就不得不跟CDL的DTD或XML Schema打交道,因为CDL就是被这鬼东西定义的嘛。我的办法是采用直观教学,相信只要您初步理解了上文解说的元素、节点、树等概念,您就能摸清楚CDL的来龙去脉。关键是CDL的定义非常简单。
为了节省篇幅(已然罗嗦到无以复加的地步了)对CDL的常识性说明请参见文林的《Specification for CDL》 、《Set of Basic Stroke Types》 及盛金标版主的中译本
(例三)
CDL的XML Schema得自文林网站(debugged by me),您也可以在附件二中找到它。
〖圖二〗
CDL文档的根元素是 cdl-list.
八边型的框框内那串糖葫芦表示cdl-list的子元素必须按一定顺序出现。不过cdl-list只有一类子元素,即cdl,所以无所谓次序,八边框下的1…∞表示cdl-list中可以包含1个至无数个cdl。Cdl后面的加号的意思是——请您观看下图。
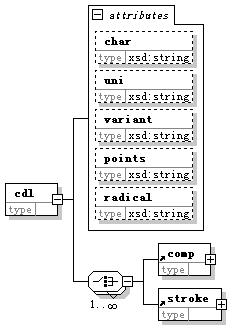
〖圖三〗
此图中cdl的支派分成两杈,上边缺脚框中的是属性(s),虚线表示可选。
char属性的值是unicode字符,如 。它的作用是就是做cdl元素的名字。
uni的值大概是数字型的unicode 编码,如<cdl char=”字” uni=”5B57” ……。
variant 据我猜测应该是unicode编码相同的异体字编号,就像“边字的65种写法”--http://www.pkucn.com/viewthread.php?tid=134101&extra=page%3D1中介绍的那种情况,打是打不出来的。比如CDL说明文档中提到的两个者字,可以分别表示为<cdl char=”者” variant=”1” ……和<cdl char=”者” variatnt=”2”……
radical应该是该字(或部件)的康熙字典部首编码。
points是该字(或部件)所占据的矩形平面空间的左上角和右下角的坐标。
因为cdl-list 中只有cdl这一种子元素,所以,我的分析是cdl元素 既用来描述“字”也用来描述“部件”,CDL中的“部件”应该都是有unicode编码的部件。
comp 和stroke是拼字用的部件和笔画。comp是对其他cdl的引用。
八角框中的符号和框下的1…∞意为“可选”,即不限定笔画、部件的出现的次数和顺序。
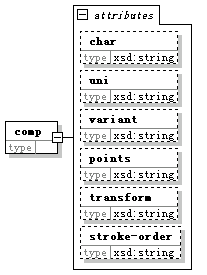
〖圖四〗
comp元素的属性跟cdl的类似,就多出来一个stroke-order(笔顺),这个属性是冗余的,因为所引用的cdl元素所包含的stroke子元素的实际排列就是该部件的笔顺。
注意:
char、uni、variant都是被引用的cdl元素的属性值。
points是针对父元素cdl的相对坐标。
transform大概是旋转、翻转一类的标识。
〖圖五〗
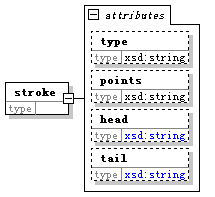
type是笔画名
points跟comp中的points一样,也是针对在父元素cdl中的位置的相对坐标
head和tail:
盛:
有关笔画头和尾的定义主要是为了跟笔画的座标点相区别。笔画的座标点一般落在笔画头部和尾部的中心。比如隶书讲究“蚕头燕尾”,那么隶书横笔头部座标点的位置在“蚕头”的中心位置,离开笔画顶端(head)的位置非常远。如果指定笔画的座标,而不定义头、尾座标,就不能显示隶书笔画的特征。
Please enable JavaScript to view the comments powered by Disqus.
blog comments powered by