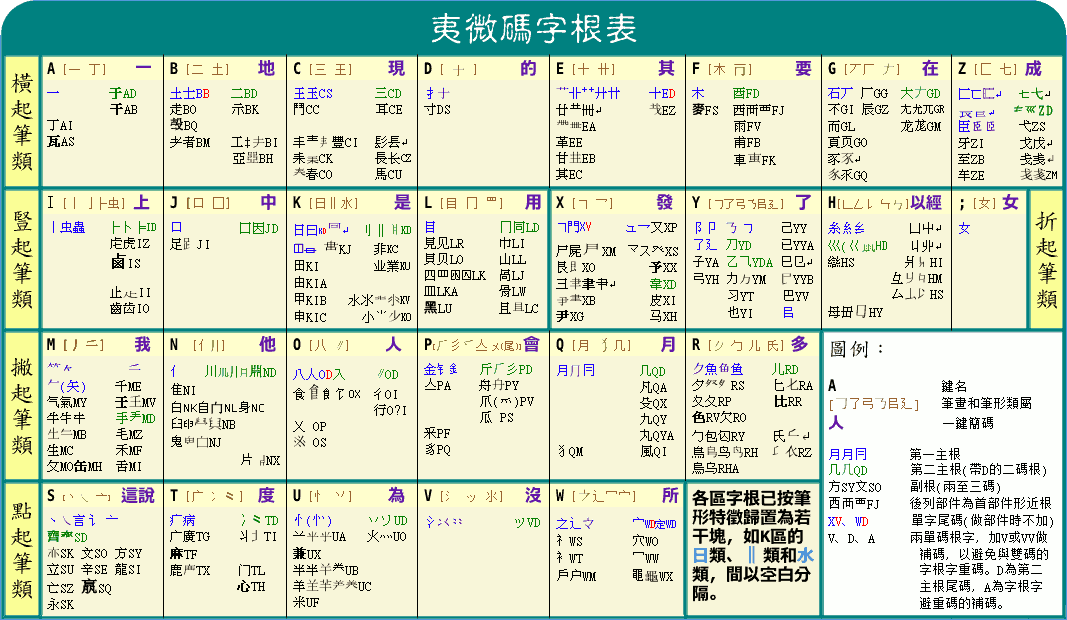
夷微碼 -- 我的鄭碼改良版
原始鄭碼:

夷微碼:
統計數據:
| 重碼 | |||||
| 字集 | 夷微 | 原始鄭碼 | 張碼 | 五筆 | 倉頡 |
| gb2312 | 189組 | 270 | 108(包括2簡?) | 254 | 218 |
| 常用6373個傳統漢字 | 160組 | 270 | 149 | 277 | 139 |
| big5 | 643組 | 1010 | 603 | 1054 | 507 |
| ids58451字 | 9285 | 10930 | 11008 | 6972 | |
釋名
何謂「夷微」?老子云:「視之不見名曰夷,聽之不聞名曰希,搏之不得名曰微。此三者不可致詰,故混為一。其上不皦,其下不昧,繩繩不可名,復歸於無物。是謂無狀之狀,無象之象,是謂恍惚。迎之不見其首,随之不見其後。執古之道,以御今之有。能知古始,是謂道紀。」
視之不見、聽之不聞就是看不見、摸不着。看不見、摸不着就是不露形跡,即所謂渾然。而渾然者也就不刺眼、不礙手、不勞神。這樣的輸入法並不屬於我們這個時空,卻是我一眾輸入法同仁所共同追求的理想境界。
RATIONALE
漢字不是像假名、字母那樣的扁平文字,而是一種層層遞歸的奇特構造。比如一個「礴」字,甫寸為尃、氵尃為溥、⺾溥為薄、石薄為礴,由甫石氵艹石五個字一層層裹起來。好像俄羅斯套娃,打開一個娃,裡邊藏着一個娃,把它打開,裡邊又是一個娃 -- 在一個定義中使用這個定義本身,這就叫遞歸。遞歸是一種簡單的邏輯,卻可以構成或解決無限複雜的問題。既然漢字的構造有遞歸的特性,輸入法的編制就必須迎合這種特性纔能接近渾然不着痕跡的目標。
夷微碼的字根(部件)是以鄭碼為基礎的。為甚麼選擇鄭碼呢?一是因為鄭碼按起始筆形特徵選定歸類了相當多的字根。漢字的遞歸不是無限遞歸,比如前例中的「礴」,最內一層的「甫」和「寸」按其真書字形都不必再拆,再拆下去就是跟人類的直觀作對。而鄭碼正好把這些不宜拆分的字或部件其常用者大致囊括其中,這些字根就是通過遞歸方式搭造搆建成千上萬個漢字的「元」件。換句話說,熟悉了鄭碼這些字根,可以省卻不少(其它輸入法中常見的)莫名其妙的拆分。二是因為鄭碼的元件編碼已在相當程度上運用了遞歸原理,以之為基礎整好可以將這一原則貫徹到底。比如說:
鄭碼以B作為筆形「二土」的編碼。M的筆形為「丿」,「耂」的編碼為BM,正是「土丿」兩筆形的組合。 又 KO =「小」, BK = 示,正是「二」+「小」; 又 K =「中間之豎」 O = 八, KO = 小 = 亅 + 八。 示的 BK中 只用 KO 的首字母K,這就是將 「小」 當成一個整體來看待。而「瓢」的編碼「FJ(覀) + B(示) + P(瓜)」,只用一個字母B表示「示」,更是將「Z二D亅八」當成整體看待。
漢字的結構可以包含很多層級、很多部件,我們不想把編碼搞得太長,就必須建立一套有效且始終一貫的省略規則。化零為整、化整為零正是一個合適的規則,並且是迎合漢字遞歸特性的好規則。
說到這裡,有心的讀者大概已經猜出了我的意圖了。夷微碼的核心,只怕不是上面貼的那張修修補補的字根圖,而是以遞歸為主導思想的一套取碼規則。
沒錯!
夷微碼的取碼法,概括起來只有三句話:
- 是偏旁優先
- 是首部件優先
- 是末部件優先
優先級依次遞降
我得先解釋一下甚麼是偏旁。很可悲的是,所有的人都認識這兩個字,然而真正懂得這兩個字的確切含義的人卻少得可憐(包括我們不少造碼人)。
國語辭典云:偏,漢字合體字的左方。旁,漢字合體字的右方。偏旁泛指漢字合體字的上下左右任一部分。
請注意這個泛指!
比如前例「礴」字,「石薄」都是礴的偏旁,「艹溥」是薄的偏旁,「氵尃」是溥的偏旁,「甫寸」是尃的偏旁,clear!
現有的形碼輸入法,(據我所知)除了倉頡和張碼都是對「偏旁」這個漢字構成的最基本概念視而不見的。原始鄭碼「首、次、次末、末」的取碼法更是跟偏旁對着幹的典型。舉幾個例子:
國 = JD囗 + 口J + 一A -- 國的「囗」裡是個「或」,凡識字的人,任誰看不出呢?鄭碼卻置之不理!不是鄭碼眼生得高,而是既定的取碼規則與漢字的自然構造相牴牾,它是「字根第一優先、略微降低重碼的取碼規則第二優先」,偏旁在這套輸入法的理念中根本沒有位置!
又:
能 = ZS厶 + R匕 + R匕
得 = OI彳 + A一 + D寸
體 = LW骨 + J口 + U䒑
稅 = MF禾 + J口 + R儿
種 = MF禾 + K日 + B二 (重 拆成 千 日 二)
機 = F木 + Z𠃋 + H戈 + O人
藝 = E艹 + B土 + B二 +Z厶
愛 = PV爫 + W心 + R夊
舒 = OD人 + X乛 + I亅
罐 = MA𠂉 + J口 + N隹
……
對字形編碼卻跟字形的構造規律對着幹,這還能有好結果嗎?
那麼,夷微碼的三優先具體又是怎麼做的呢?
如「體」字。偏旁優先:是合體,就先分出偏旁「骨 + 豊」。接着,第一偏旁是字根,首部件優先,意味着:字根為首旁的取全碼,為合體偏旁首部件的取儘可能多的碼。骨全碼為LW,全取。夷微碼每辭條最多4碼,那就還剩兩碼可取。「豊」又可分出兩旁,那就前後各分配1碼。「曲」=「曰+‖」,首部件優先,取曰的碼。因「曲」只分配了1碼,那就取1碼K(曰剛好是1碼根)。「豆」也只分得一碼,豆不是字根,=「一+口+䒑」。注意,這是字的末旁!末部件優先一方面即指末旁中必須取末部件!那就把這一碼交給「䒑」。「䒑」的全碼是UA,取U。
倘如「豆」字呢,一、口、䒑,一、口是單碼根,取完剩兩碼的空間。「末部件優先」又意味着當前面該取的都取過之後,剩兩個及以上空碼位時,且末根為多碼根的,可以取儘量多的碼以填補空位。䒑為雙碼根,那麼 一A口J䒑UA,這樣取就湊足了4碼。
如「英」字。艹單碼E,冂雙碼LD,大雙碼GD,這怎麼取? 看上面規則的次序!首部件beats末部件。英=艹A + 央?,央= 冂LD + 大G。Get it ?
如「愛」字,IDS把一個合體字最多拆成三塊。愛依字理是「Z㤅夊」,我們不去管它。直觀上,大概沒有誰會把愛先從「爫冖」間斷開,因為還有受、爱、舜,習慣成條反,我們會下意識地覺得,爫冖結合相對較緊密。那就把愛以心為中旁分成3塊吧。首旁本身是合體,之外還有兩旁--或者首旁為合體,末旁也是合體的二合字,也是一樣(如「能聽」)--一遇到這類字就是「前二、後二」。前二了,爫雖全碼為PV,但它不是獨佔一旁,那就爫1、冖1;後二呢,雖說末部優先,那它也蓋不過偏旁優先,因而心1、夊1。「聽」字:耳+𡈼為左旁,㥁為右旁,耳1、𡈼1不用說了,㥁怎麼 分呢?咋分都沒關係!首部優先,分給「十」1碼;末部優先,分給「心」1碼。DONE!
如「怠」,這字正常人都會分成「台」+「心」,心是獨體的,則首旁最多可分得3碼。厶全碼為HS,首部優先,怠 = 厶HS+口J+心T。
能 = Z厶 + Q月 + R匕 + R匕
得 = OI彳 + K日 + D寸
體 = LW骨 + K日 + U䒑
稅 = MF禾 + O八 + R儿
種 = MF禾 + M千 + B二 (重 拆成 千 日 二)
機 = F木 + H𠃋 + Z戈 + O人 (因為「𢆶+戈」是一旁,取碼未變,觀念卻變了。「𢆶+戈」中𠃋首、戈末。)
藝 = E艹 + Q丸 + B二 +Z厶(藝=蓺 + 云)
愛 = P爫 + W冖 + W心 + R夊
舒 = O人 + M舌 + XX予 (只字的末根有填空位的權力,「舍」作為偏旁,其末根舌只能取1碼)
罐 = MH缶 + E艹 + N隹
說起來似乎挺複雜,其實拆幾個字就能明白。這套取碼法,實質上就是偏旁優先、輪廓優先。首旁為單根的更優先一點,那是因為,那類根多是高頻部首,對避重碼的效用很大。有些常用字,這樣取法嫌囉唆的,往往都有簡碼(英E LD G → E L G)。夷微碼的簡碼也比原始鄭碼的容易,如「得」 彳OI 日K 寸D → OK, 而原始鄭碼彳OI 一A 寸D → OK,K是哪來的呢?
